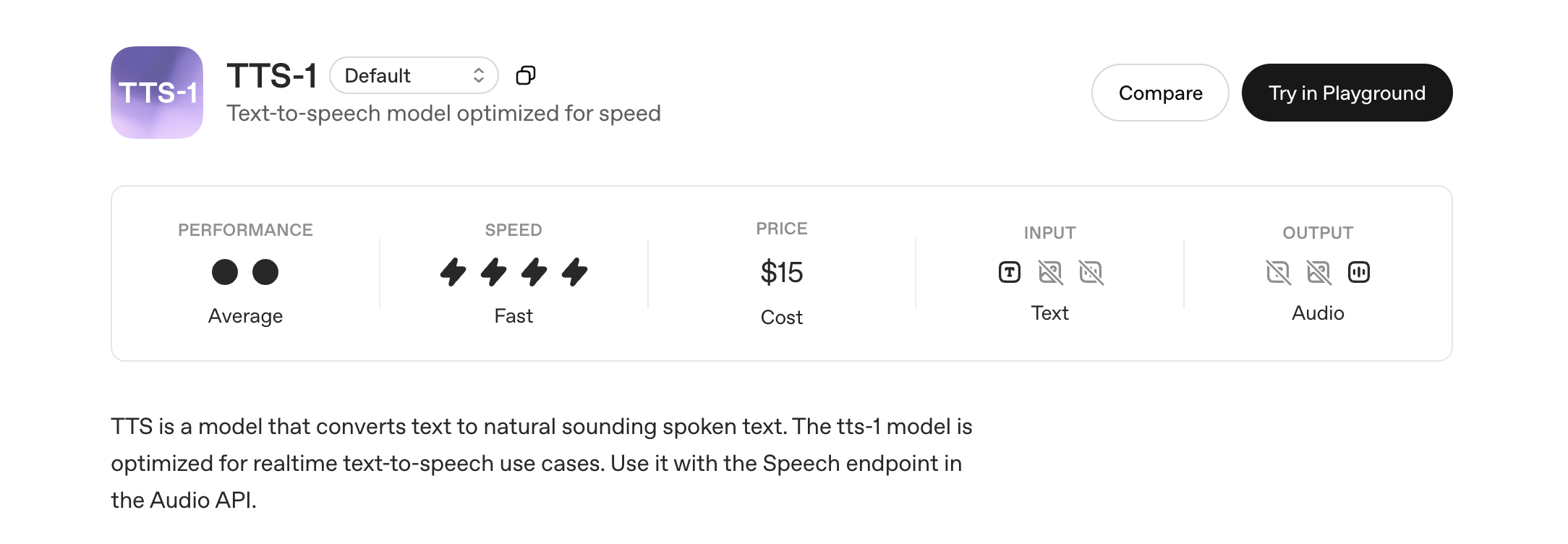
1. OpenAI TTS-1: Optimized for Speed
The `tts-1` model is OpenAI's go-to for real-time text-to-speech applications where speed is paramount. It's designed to deliver audio quickly, making it ideal for interactive experiences like chatbots, live voice assistants, or any scenario where low latency is critical.
- Supported Languages: `tts-1` supports a wide range of languages, including English, Spanish, French, German, Italian, Portuguese, Dutch, Russian, Chinese, Japanese, Korean, and many more. OpenAI continuously expands its language support.
- Speed: As its primary optimization, `tts-1` offers fast generation speeds, often producing audio almost instantaneously.
- Performance (Audio Quality): While optimized for speed, `tts-1` still delivers good quality, natural-sounding speech. It's generally suitable for most applications where clarity is important but ultra-high fidelity isn't the absolute top priority.
Audio Sample (TTS-1)
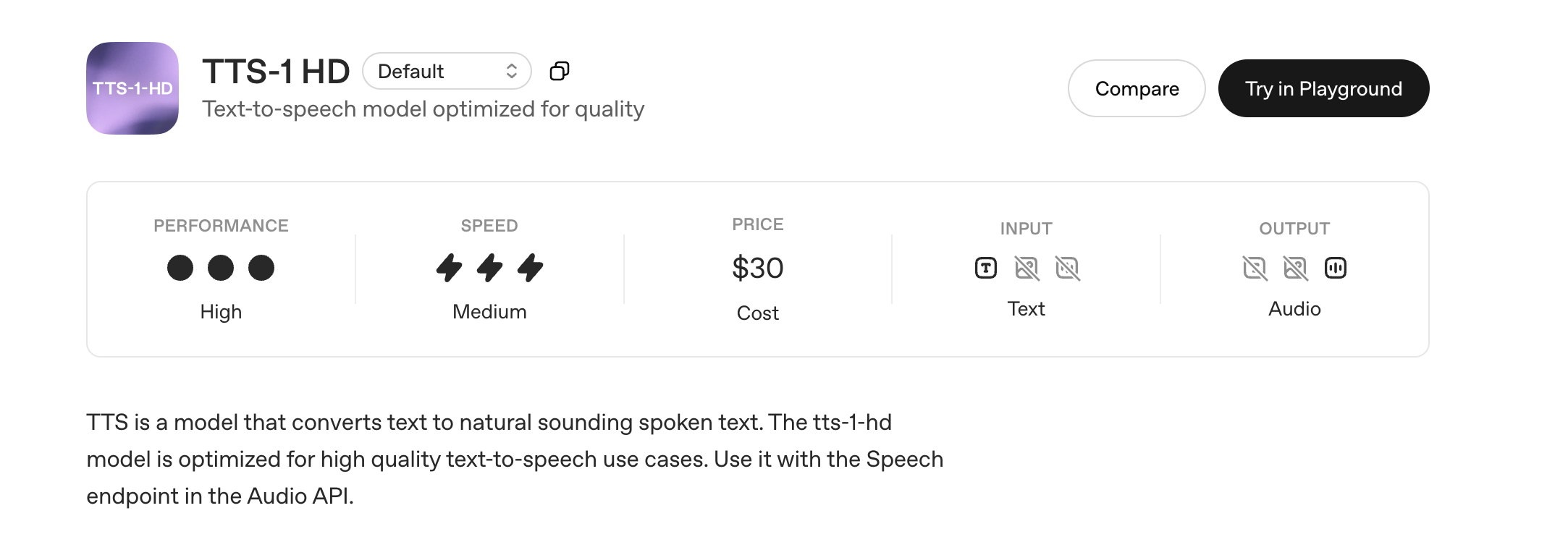
2. OpenAI TTS-1 HD: Optimized for Quality
For applications where audio fidelity is paramount, `tts-1-hd` steps in. This model prioritizes high-quality, natural-sounding speech, making it perfect for professional voiceovers, audiobooks, podcasts, or any content where a premium listening experience is desired.
- Supported Languages: Similar to `tts-1`, the `tts-1-hd` model supports a broad spectrum of languages, ensuring high-quality output across diverse linguistic needs.
- Speed: While `tts-1-hd` delivers superior quality, it does so at a slightly slower pace than `tts-1`. Its speed is categorized as "Medium," meaning it's not ideal for real-time, low-latency scenarios but perfectly acceptable for pre-generated audio content.
- Performance (Audio Quality): This is where `tts-1-hd` shines. It produces highly expressive and natural-sounding voices, minimizing robotic artifacts and delivering a rich, clear audio experience.
Audio Sample (TTS-1 HD)
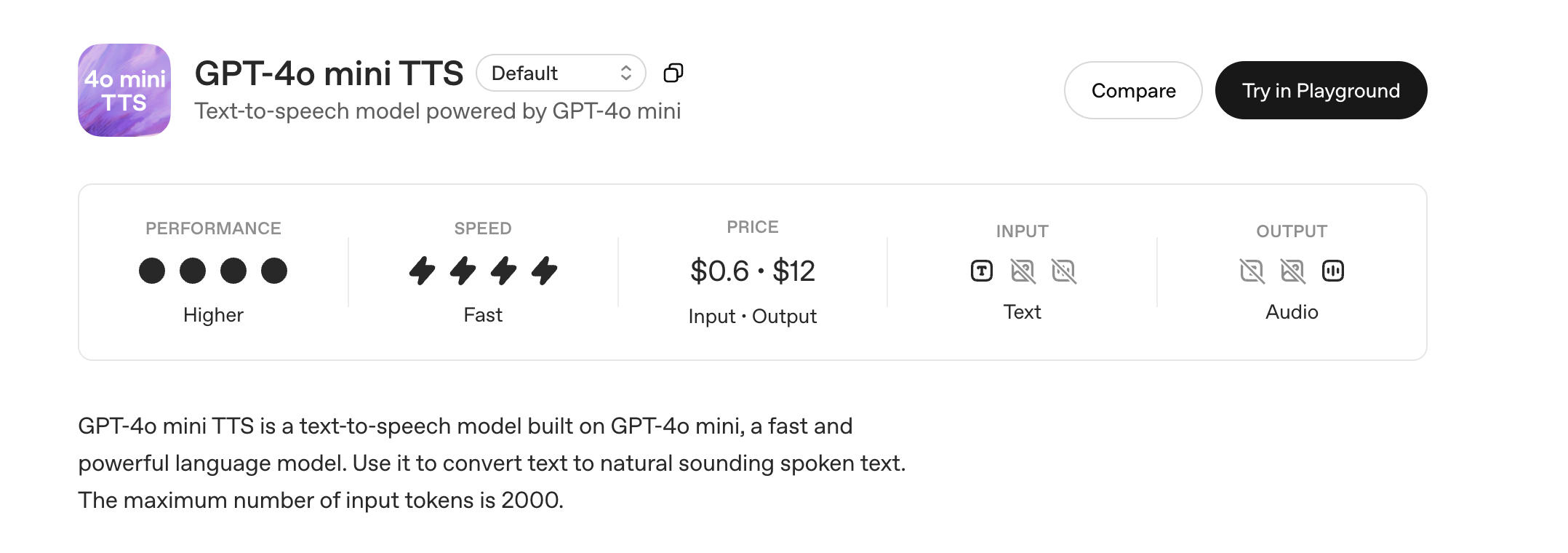
3. OpenAI GPT-4o Mini TTS: The New Contender
The `gpt-4o-mini-tts` model is a newer addition, built on the powerful `gpt-4o mini` language model. It aims to offer both high performance and fast generation, potentially being the best OpenAI TTS model.
- Supported Languages: Leveraging the multilingual capabilities of `gpt-4o mini`, this TTS model supports a vast array of languages, making it highly versatile for global applications.
- Speed: `gpt-4o-mini-tts` is designed for fast generation, similar to `tts-1`, making it suitable for responsive applications.
- Performance (Audio Quality): It boasts even "Higher" performance, suggesting an improved audio quality over `tts-1` and `tts-1-hd` while maintaining speed. This makes it a perfect option for all applications.
- Input Token Limit: A key detail for `gpt-4o-mini-tts` is its maximum input token limit of 2000, which is important to consider for longer texts.
Audio Sample (GPT-4o Mini TTS)
Comparison Summary
| Feature | TTS-1 | TTS-1 HD | GPT-4o mini TTS |
|---|---|---|---|
| Primary Focus | Speed | Quality | Speed and Quality (Higher Performance, Fast Speed) |
| Audio Quality | Good / Average | High | Higher |
| Generation Speed | Fast | Medium | Fast |
| Supported Languages | Broad | Broad | Broad |
| Ideal Use Case | Real-time applications, quick previews | Audiobooks, professional voiceovers, podcasts | General applications needing good quality and speed |
| Input Token Limit | 4096 | 4096 | 2000 |
| Cost per 1M Tokens | 15 USD | 30 USD | 12 USD |
Conclusion
OpenAI offers a robust suite of text-to-speech models, each with its strengths. If you need lightning-fast responses for interactive applications, `tts-1` and `gpt-4o-mini-tts` is your best bet. For the highest possible audio fidelity, `tts-1-hd` and `gpt-4o-mini-tts` delivers a premium experience. The `gpt-4o-mini-tts` model emerges as a perfect option, offering a both higher quality and fast generation. The cost of `gpt-4o-mini-tts` is 12 USD per 1M tokens, while `tts-1` costs 15 USD and `tts-1-hd` costs 30 USD per 1M, making it the best choice for any application.